Abstract
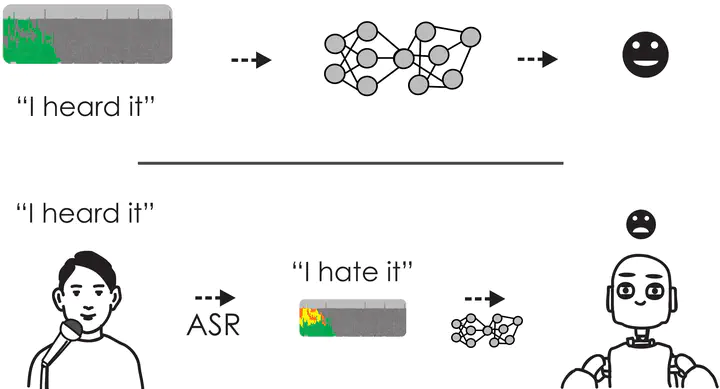
Previous work on emotion recognition demonstrated a synergistic effect of combining several modalities such as auditory, visual, and transcribed text, to estimate the affective state of a speaker. Among these, the linguistic modality is crucial for the evaluation of an expressed emotion. However, manually transcribed spoken text cannot be given as input to a system practically. We argue that using ground truth transcriptions during training and evaluation phases leads to a significant discrepancy in performance compared to real-world conditions, as the spoken text has to be recognized on the fly and can contain speech recognition mistakes. In this paper, we propose a method of integrating an automatic speech recognition (ASR) output with a character-level recurrent neural network for sentiment recognition. In addition, we conduct several experiments investigating sentiment recognition in human-robot interaction in a noise realistic scenario which is challenging for the ASR systems. We quantify the improvement compared to using only the acoustic modality in sentiment recognition. We demonstrate the effectiveness of this approach on the Multimodal Corpus of Sentiment Intensity (MOSI) by achieving 73,6% accuracy in a binary sentiment classification task, exceeding previously reported results that use only acoustic input. In addition, we set a new state-of-the-art performance on the MOSI dataset (80.4% accuracy, 2% absolute improvement).